What is Hydra?
When working with free text search, for example using Apache Solr, the quality of the data in the index is a key factor of the quality of the results delivered. Hydra is designed to give the search solution the tools necessary to modify the data that is to be indexed in an efficient and flexible way. This is done by providing a scalable and efficient pipeline which the documents will have to pass through before being indexed into the search engine.
Architecturally Hydra sits in between the search engine and the source integration. A common use-case would be to use Apache ManifoldCF to crawl a filesystem and send the documents to Hydra which in turn will process and dispatch processed documents to Solr for indexing.
Why name it Hydra?
The mythical Hydra is scaly many-headed beast, tasked with guarding the underworld. Each head on it's own can chew through any foe, and should an adventurer manage to cut one head off, it will grow back.
The modern-day Hydra is also a many-headed beast. Any amount of heads (or processing nodes) can be created, each capable of chewing through any kind of document. Adding a new head, and thereby scaling your processing capacity, is as easy as starting the framework on a new machine. The processing nodes are designed to be entirely independent of each other, and thus if you cut one head off, it will not affect the capability of the pipeline. Though, of course, there will be fewer teeth available to chew your foes... err... documents.
While it's up to you to reattach a head should it be cut off, Hydra does regenerate it's teeth - the processing stages. Should one fail, for instance if your PDF Parser runs across a corrupted PDF and crashes, it will be automatically restarted and begin processing new documents.
Talks
Hydra has been presented at a couple of conferences:
Hydra - an open source processing framework (Berlin Buzzwords 2012)
Introducing Hydra – An Open Source Document Processing Framework (Lucene Revolution 2012)
Description
The pipeline framework design is intended to be easily distributed, very flexible and to allow easy testing and development. Because of its distributed data crunching nature, we've decided to name it Hydra.
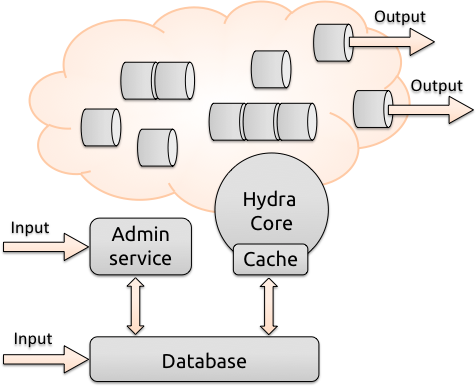
Hydra is designed as a fully distributed, persisted and flexible document processing pipeline. It has one central repository, currently an instance of a MongoDB document store, that can be run on a single machine or completely in the cloud. A worker node (Hydra Core) reads a pipeline configuration from this central repository and loads the associated processing stages - which are packaged as jar files. The stages in those jar files are then, for isolation purposes, launched by the main process as separate JVM instances or together in a stage group. This is done to ensure that problems such as Tika leaking memory and running out of heap space on a problematic document will not bring the whole pipeline to a halt. The core will monitor the JVMs and restart the stages if necessary.
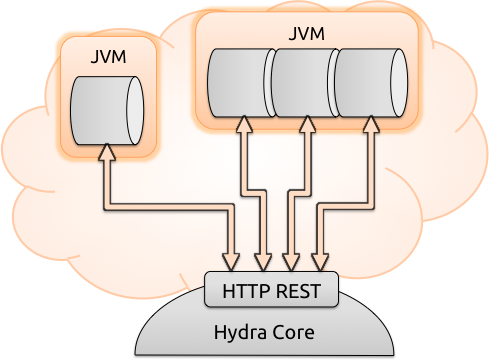
All communication between the stages and the core framework happens via REST. Because of this, one can test processing stages in development by simply running them from any IDE such as Eclipse, pointing them to an active node. This eliminates the need for time consuming WAR packaging/deployment found in e.g. OpenPipeline. The stages, running in their own JVMs, will then fetch documents relevant for their processing purpose from MongoDB, e.g. a “Static Writer” stage would fetch any and all documents, while a more specialized node might only fetch documents that have or lack a certain field. This allows configuration of both the classic “straight” pipeline where all documents pass through all processing nodes (in order, if necessary), and asymmetrical pipelines that can fork depending on the content of the document.
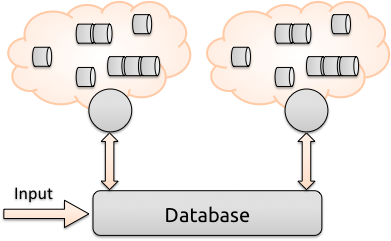
All administration of the pipeline, as well as traceability, are handled directly through an administrator interface communicating with the central repository (MongoDB). To add processing power to the pipeline, it is as simple as starting a new worker node on another machine, pointing to the same pipeline configuration in MongoDB.
Design Goals
Hydras key design goals are for it to be:
Scalable: the central repository as well as the number of worker nodes can scale horizontally with little to no performance loss.
Distributed: any processing node can work on any document - a single document may be processed on any number of physical machines
Fail-safe: if a processing node goes down, this will not affect the documents in the pipeline, which are persisted centrally, and any other node can simply and automatically pick up where the other left off.
Robust: all stages run in separate JVMs, thus allowing for instance Tika to crash in a separate JVM, which will be automatically restarted, without stopping the processing pipeline for less problematic documents.
Easy to use/configure: stages can be run from your IDE during development, allowing testing against the actual data in the repository.
Downloads
To get started, download the latest release and have a look at the readme on Github.
Latest release
Go to the releases page on Github to get the latest release.
Older releases
Get involved
The community is based around the github repository, along with a Google Groups mailing list:
Mailing list: Hydra on Google Groups (hydra-processing@googlegroups.com)
Issue tracking: github.com/Findwise/Hydra/issues
Maven artifact group: com.findwise.hydra
License
Hydra is licensed under the Apache License, Version 2.0
